
What is Big Data
Big Data is the ocean of information we swim in every day – vast zetabytes of data flowing from our computers, mobile devices, and machine sensors.
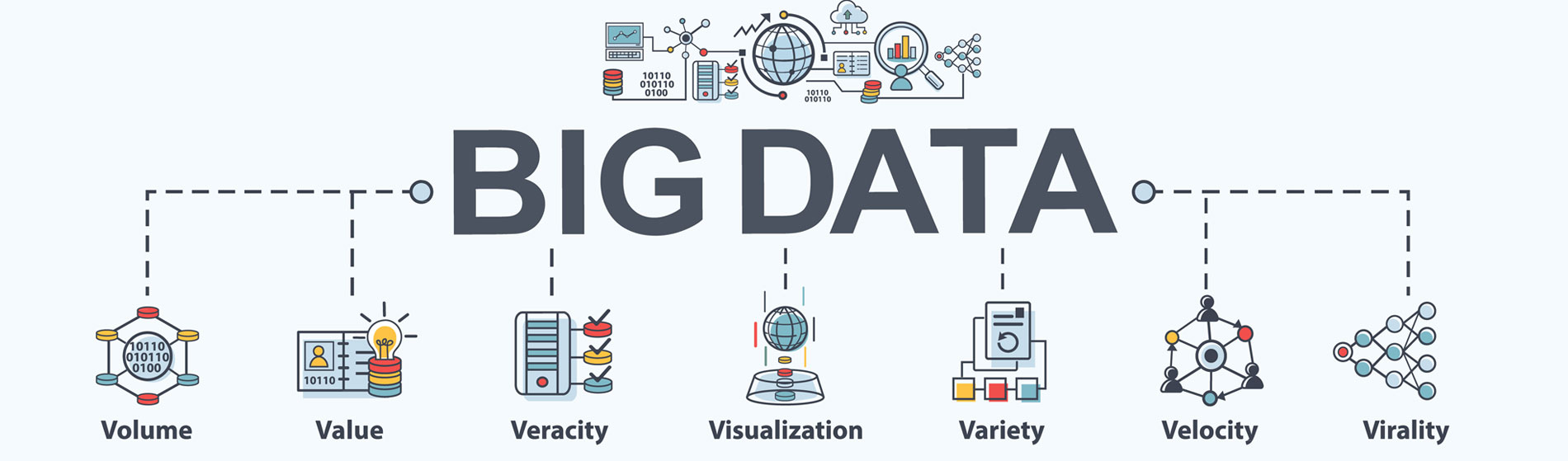
Big Data is the ocean of information we swim in every day – vast zettabytes of data flowing from our computers, mobile devices, and machine sensors. This data is used by organisations to drive decisions, improve processes and policies, and create customer-centric products, services, and experiences. Big Data is defined as “big” not just because of its volume, but also due to the variety and complexity of its nature. Typically, it exceeds the capacity of traditional databases to capture, manage, and process it. And, Big Data can come from anywhere or anything on earth that we’re able to monitor digitally. Weather satellites, Internet of Things (IoT) devices, traffic cameras, social media trends – these are just a few of the data sources being mined and analysed to make businesses more resilient and competitive.
The traditional data types were mainly structured ones and they were used to fit easily into the regional database. However, big data has led to the introduction of newer data varieties – unstructured and structured.
Novus 365 Technologies uses a mix of technologies to build a data science software platform for Analysts and Data Scientists to explore, prototype, and analyze tons of unstructured or structured data efficiently.
The true value of Big Data is measured by the degree to which you are able to analyse and understand it. Artificial intelligence (AI), machine learning, and modern database technologies allow for Big Data visualisation and analysis to deliver actionable insights – in real time. Big Data analytics help companies put their data to work – to realise new opportunities and build business models. As Geoffrey Moore, author and management analyst, aptly stated, “Without Big Data analytics, companies are blind and deaf, wandering out onto the Web like deer on a freeway.”
Types of Big Data:
The core of cloud computing is made at back-end platforms with several servers for storage and processing computing. Management of Applications logic is managed through servers and effective data handling is provided by storage. The combination of these platforms at the backend offers the processing power, and capacity to manage and store data behind the cloud.
Structured data : This kind of data is the simplest to organise and search. It can include things like financial data, machine logs, and demographic details. An Excel spreadsheet, with its layout of pre-defined columns and rows, is a good way to envision structured data. Its components are easily categorized, allowing database designers and administrators to define simple algorithms for search and analysis. Even when structured data exists in enormous volume, it doesn’t necessarily qualify as Big Data because structured data on its own is relatively simple to manage and therefore doesn’t meet the defining criteria of Big Data. Traditionally, databases have used a programming language called Structured Query Language (SQL) in order to manage structured data. SQL was developed by IBM in the 1970s to allow developers to build and manage relational (spreadsheet style) databases that were beginning to take off at that time.
Unstructured data : This category of data can include things like social media posts, audio files, images, and open-ended customer comments. This kind of data cannot be easily captured in standard row-column relational databases. Traditionally, companies that wanted to search, manage, or analyse large amounts of unstructured data had to use laborious manual processes. There was never any question as to the potential value of analysing and understanding such data, but the cost of doing so was often too exorbitant to make it worthwhile. Considering the time it took, results were often obsolete before they were even delivered. Instead of spreadsheets or relational databases, unstructured data is usually stored in data lakes, data warehouses, and NoSQL databases.
Semi-structured data : As it sounds, semi-structured data is a hybrid of structured and unstructured data. E-mails are a good example as they include unstructured data in the body of the message, as well as more organisational properties such as sender, recipient, subject, and date. Devices that use geo-tagging, time stamps, or semantic tags can also deliver structured data alongside unstructured content. An unidentified smartphone image, for instance, can still tell you that it is a selfie, and the time and place where it was taken. A modern database running AI technology can not only instantly identify different types of data, it can also generate algorithms in real time to effectively manage and analyse the disparate data sets involved.